第5回目は、学習のテクニックの1つである「データオーグメンテーション」について説明します。
ディープラーニング(Deep Learning:深層学習)は、学習時に最適化するパラメータ数が多いため、数万、数十万枚の学習データが必要だと言われています。しかし、十分な量の学習データを用意できないことが多々あります。あるいは、さらに認識性能を高めたいと考えることがあると思います。そのような際に活躍するのが、データオーグメンテーションというテクニックです。
データオーグメンテーションとは?
データオーグメンテーション(データ拡張)とは、学習データ(訓練データ)の画像に対して平行移動、拡大縮小、回転、ノイズの付与などの処理を加えることで、データ数を人為的に水増しするテクニックです。例えば、3000枚の画像を用意し、下記のデータオーグメンテーションを施したとします。
・平行移動:縦横それぞれ-20画素、0画素、20画素
・回転:-5°、0°、5
・拡大縮小:拡大率0.9、 1.0、 1.1
データオーグメンテーション後の画像は、3000枚×3×3×3×3=24万3000枚となります。実際に運用する際の入力画像は、学習データに含まれる画像と異なりカメラの距離がやや近かったり、少し傾いていたりすることが十分にあり得ます。データオーグメンテーションを用いることでデータ数を水増しできるだけでなく、このような画像のずれに対してもロバストになるというメリットがあります。
データオーグメンテーションで用いる処理
データオーグメンテーションで用いる処理は、前述のものを含めると例えば下記のようなものがあげられます。平行移動、回転、拡大縮小は、実際にとり得る範囲でデータを拡張すると良いでしょう。背景の置換は、屋外の歩行者のように、背景が千差万別な場合に有効です。具体的には、人の領域のみを抽出し、背景を様々な画像に置き換える処理を行うことになります。
・平行移動
・回転
・拡大縮小
・左右反転
・上下反転
・射影変換
・背景の置換
・ノイズの付与
など
データオーグメンテーションの一例
■左右反転
左右反転は、人の顔や全身の検出などに有用な処理です。この処理を施すことで、右から見た顔の精度は高いが左から見た顔は苦手といった、データの偏りの影響を緩和することも期待できます。
ただし左右反転や上下反転は、識別したい対象によっては適用することができないので注意が必要です。例えば、文字認識の場合、多くの文字は左右、上下を反転させてしまうと存在し得ない文字となってしまいます。
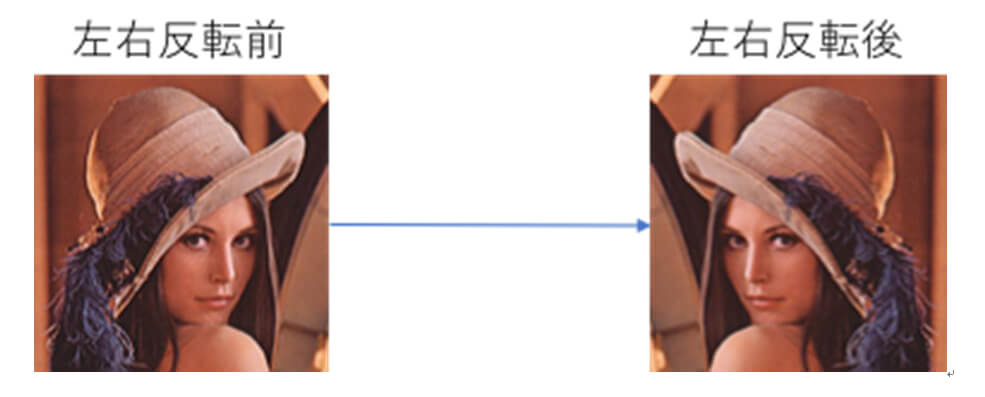
図1 左右反転の例
■射影変換
識別したい対象がCDのジャケットや本の表紙のように平面の場合は、射影変換によるデータ拡張が有効です。射影変換の概要は図2の通りです。平面パターンは、射影変換により異なる視点から撮影したパターンを生成することができます。
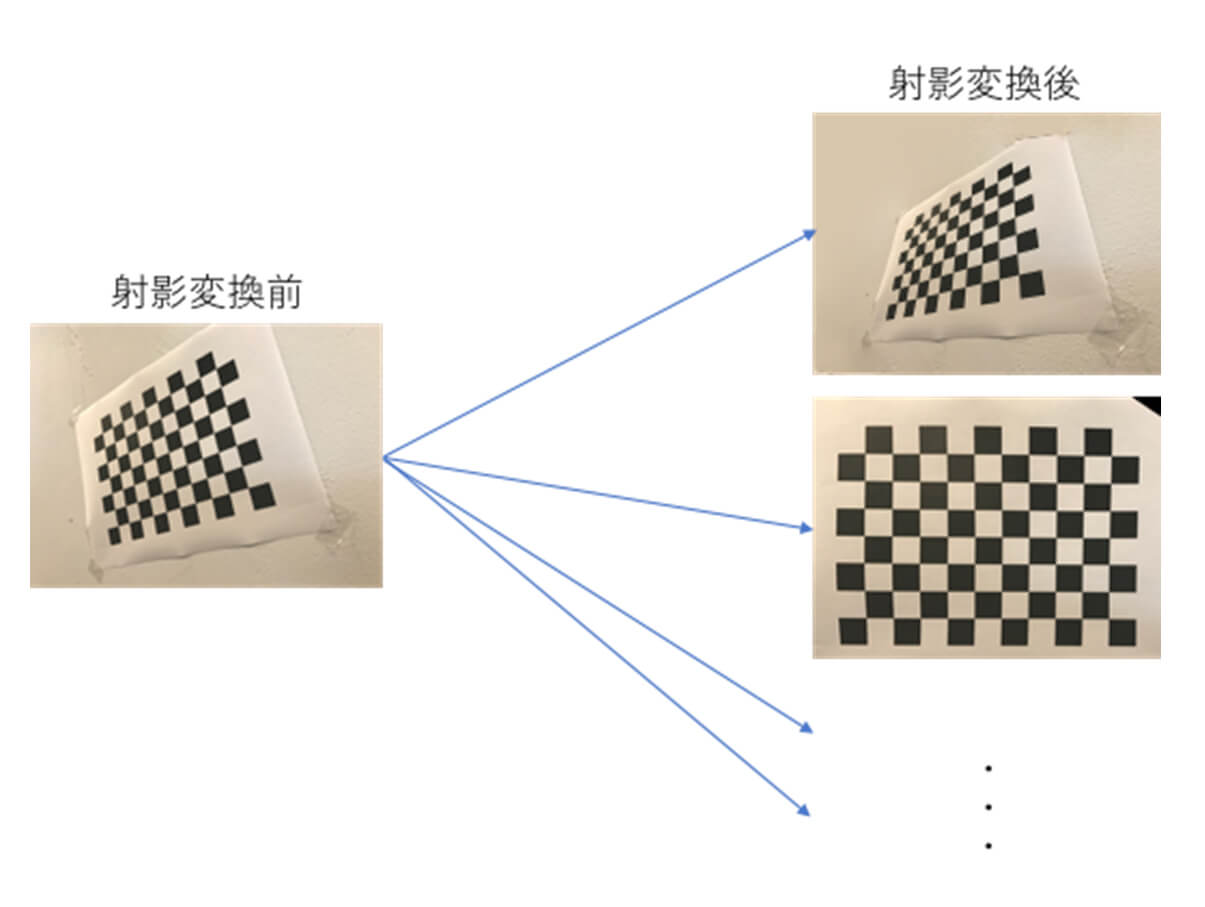
図2 射影変換の例
次回は、ニューラルネットワークの学習の基礎知識である「勾配法」についてご紹介します!