第21回目の今回は、顔検出・人検出についてもう少し詳しく解説します。
説明を簡略化するために、「顔」と「人」のみを検出対象として説明しますが、検出対象が車や自転車であっても同じ枠組みで検出することができます。
顔検出の処理フロー
顔検出には2つのフェーズがあります(図1)。
1つは、事前に行う学習データを用いた学習フェーズです。もう1つは、学習フェーズで学習した結果を用いた識別フェーズ(テストフェーズ)です。
学習画像は、顔画像(ポジティブデータ)と、顔以外の画像(ネガティブデータ)を用意します。画像のサイズが均一でない場合は、リサイズ処理により画像のサイズを統一する必要があります。そして、画像から特徴量を抽出し、学習して、学習結果を保存しておきます。
識別フェーズでは、入力画像が学習時の画像サイズと異なっている場合は、まず画像のリサイズを行います。そして、学習時と同じ特徴量を抽出し、学習結果を用いて映っている画像が顔か、顔以外かを識別します。このとき、入力画像が図2のようで、上半身全体が写っている画像から顔を見つけたい場合は、ウィンドウを2次元スキャンして探索することになります。顔の大きさが未知の場合は、ウィンドウのサイズを変えて、複数回2次元スキャンを行う必要があります。
-
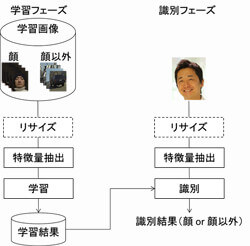
図1 従来の顔検出の処理フロー
-
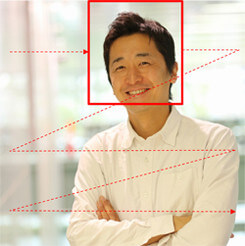
図2 顔画像の探索処理
特徴量
■Haar-like特徴量
人間は何をもって顔と認識しているのでしょうか? 図3のように顔画像をぼかしても、顔として認識することができます。これは、目と肌の明暗差、鼻の凹凸による明暗差などから、顔を顔と認識しているのだと言えます。

図3 ぼかした顔画像
このような顔の特徴を抽出するために、顔検出ではHaar-like特徴がよく用いられます(図4)。左右方向や上下方向の明暗差を判定するためのHaar-likeパターンと呼ばれるマスクを用いて、目、鼻、口などの特徴量を抽出します。例えば、目の領域であれば、上下方向に明暗の変化があります。鼻の領域は、左右方向に明暗の変化が現れます。この顔の普遍の特徴を、Haar-likeパターンで抽出するというアプローチです。

図4 Haar-like特徴量
■HoG特徴量
Haar-like特徴量の他に、HoG特徴量というものもあります。顔の場合は、目、鼻、口付近の明暗差が大きく変わらないため、Haar-like特徴が有用でした。しかし、人検出の場合は、服や体の姿勢の差異によって、局所的な明暗差は大きく変化してしまいます。そのため人間の体を検出対象とした場合、各部位の明暗差よりも、顔や肩の輪郭情報がより重要になってきます。
そこで、HoG(Histograms of Oriented Gradients)という特徴量が提案されました(図5)。HoG特徴量は、画像を格子状に分割し、各格子の局所領域内の輝度勾配方向を求め、輝度勾配方向をヒストグラム化したものを特徴量とするものです。これにより、肩であれば斜めの輝度勾配が多く含まれる、首であれば水平方向の輝度勾配が多く含まれるといった、輪郭の特徴を抽出することができます。
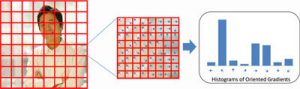
図5 HoG特徴量
Haar-like、HoG以外にも、Joint Haar-like、Joint HoG、Shapeletなど様々な特徴量が提案されています。
次回は、抽出した特徴量を用いて、学習・識別を行う識別器について解説します!