第23回目の今回は、ディープラーニング(Deep Learning:深層学習)について説明します。
コンピュータビジョン分野では、Deep Convolutional Neural Network(以下、CNN)がよく用いられます。
ニューラルネットワーク(Neural Network)とは?
ニューラルネットワーク(Neural Network)は、脳を模倣した機械学習です。ニューラルネットワークは長年のあいだ、入力層、中間層(隠れ層)、出力層のシンプルな構造が主でした(図1)。
手書き数字の認識を例に説明すると、入力層(x1, x2, ……, xn)には各ピクセルの輝度値を入力します。縦10画素×横10画素の画像であれば、nは100となります。そして、出力層(y1, y2, ……, ym)は、手書き数字が、0から9のいずれなのかを出力することになるので、mは10です。
学習フェーズで各ノード間の重みを求めておくと、未知の画像が入ってきたときに、書かれている数字が0から9のいずれなのかを識別できるというわけです。
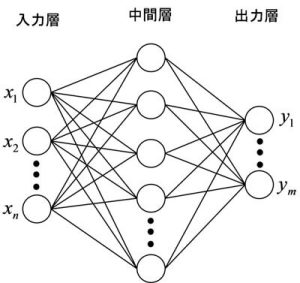
図1 ニューラルネットワークの例
ディープラーニング(Deep Learning)とは?
長年の間、ニューラルネットワークは図1のようなシンプルな構造でした。ニューラルネットワークのブームが去った後、ニューラルネットワークに代わる機械学習手法として、第22回でご紹介したSVMやRandom Forestなどの研究が進められてきました。そしてその後、中間層を何層も重ねたDeep Neural Networkにより、高い識別性能を得ることに成功し、ニューラルネットワークのブームが再びやってきました。学習技術の進歩、大量の学習データ、PCの性能向上により、深い構造を持つニューラルネットワークを利用できるようになったのです。
コンピュータビジョン分野では、主にCNNが用いられます。2次元配列の構造を持つ画像と、二次元配列のフィルタによる畳み込み処理の相性が良いことが、CNNが用いられる理由だと思います。
CNN(Convolutional Neural Network)の概要
CNNの概要は、図2のとおりです。入力画像がRGBのカラー画像であれば、入力は3チャンネルとなります。その入力画像にフィルタをかけ、足し合わせることでひとつのマップを生成します。そしてPooling処理でマップのサイズを縮小し、最後はニューラルネットワークの入力層にマップの値を入力する構造です。
Poolingは一般的にはMax PoolingかSum Poolingを用います。Max Poolingは、たとえば2×2の小領域の中から最大の値のみを取り出します。Sum Poolingは、小領域中の値の合計値を求めます。
学習フェーズでは、ニューラルネットワークのノード間の重みに加え、フィルタの係数を求めることになります。フィルタを複数種類用いて、複数のマップを作成することもできます。さらに、フィルタを用いた畳み込み処理、Pooling処理を何層にも重ねることもできます。
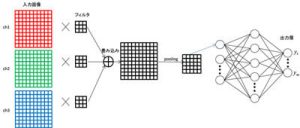
図2 CNNの概要
CNNでは、前回までに解説した顔検出、人検出技術のように、Haar-likeやHoGといった特徴量を設計する必要がありません。フィルタのパラメータを学習フェーズで求め、そのフィルタが特徴抽出器となります。つまり、特徴量の設計まで自動でやってくれる優れものなのです。
Caffe、Chainer、TensorFlowといったDeep Learningのフレームワークを用いることで、比較的容易にコーディングできます。
次回からは、人間の視線の計測について紹介します!