第32回目となる今回は、複数の人物が存在するシーンで、どこのエリアが人々の注意を集め得るかを推定するSocial Saliency Predictionについて紹介します(参考文献: Park and Shi, “Social Saliency Prediction”, CVPR’15)。
Joint Attention
まずは、Social Saliency Predictionの関連研究について触れておきます(参考文献:Park, Jain, and Sheikh, “3D Social Saliency from Head-mounted Cameras”, NIPS’12)。
この研究では、図1のように複数の人物が存在するシーン中で、全員が頭部にカメラを装着していることを前提として、複数の人物がどのエリアを同時に見ているか(Joint Attentions、Gaze Concurrences)を推定する手法を提案しています。各カメラから得られた画像系列を入力とし、SfM(Structure from Motion)の技術を用いて各カメラの位置、姿勢を求めます。その結果から、図2のように3次元空間中のどのエリアを同時に見ているかを推定できます。
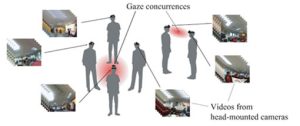
図1 “3D Social Saliency from Head-mounted Cameras”の概要

図2 複数のHead-mounted Cameraを用いたJoint Attentionの推定結果
Social Saliency Prediction
先に述べた複数のHead-mounted Cameraを用いたJoint Attentionの推定結果を学習データとして用い、人の位置とJoint Attentionの関係性を学習します。具体的には、人物間の相対的位置を特徴量とし、Joint Attentionとの距離が閾値以内の位置をPositive、閾値以上の位置をNegativeとして、2クラスのアンサンブル分類器を学習します。
Joint Attention推定時は、1台のHead-mounted CameraからSfMを用いて複数の人を検出し、位置を求めます。そしてその複数の人の位置を入力として、学習済みの分類器を用いてJoint Attentionを推定します(図3、動画1)。この手法では、検出した人の視線や頭部の方向を求める必要はなく、位置のみからJoint Attentionを推定できます。画像中から人を検出し、視線方向または頭部の方向を求めることは技術的には可能ですが、安定かつ高精度に求めることが難しいため、位置のみから推定できるというのは大きなメリットです。
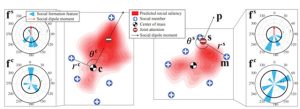
図3 人の位置関係からのSocial Saliencyの推定
動画1 Social Saliency Predictionの結果
学習には複数のHead-mounted Cameraを用いていますが、実際にSocial Attentionを求めるときは1台のカメラのみあれば推定できます。店舗内の人の注視領域の推定など、広く応用できるかもしれません。
次回は、インターネット上の画像群からTime-lapse映像を自動生成する手法の概要について説明します!