第53回目は、処理速度の早いYOLO[1]について説明します。
YOLOは、You Only Look Onceの略で、画像を入力するとsliding windowsで順次処理することはせず、1回で物体を検出します。精度はややFaster R-CNNに劣るものの、大幅な処理速度向上(45〜155FPS)を達成していることが最大の特徴です。
YOLOは複数のバージョンがリリースされていますが、ここでは初代のYOLOについてご紹介します。
YOLOの概要
YOLOでは、まず入力画像を縦横448画素にリサイズします。そしてConvolutional networkで物体候補を求め、極大値以外の値を0に抑制し、その後に閾値処理により最終的な物体検出結果を得ます(図1)。
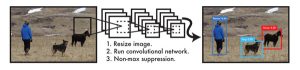
図1 YOLOの概要
画像の左上から順番に部分画像を切り出していくsliding windowや、R-CNNで用いられていたRegion proposalのようなアプローチの代わりに、YOLOでは画像をグリッド状のセルに分割します(図2)。図2の例では7×7に分割しています。そしてセルごとに、物体が存在し得る領域の外接矩形と信頼度(図2中央上:Bounding boxes + confidence)、クラス確率(図2中央下:Class probability map)を求めます。そして、物体が存在し得る領域の外接矩形の予測結果と、クラス(物体の種別)の確率マップを統合し最終的な検出結果を得ます(図2右)。
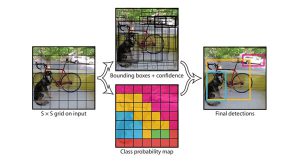
図2 グリットごとの物体検出
YOLOのネットワーク
YOLOで用いられているディープラーニングのネットワークは図3の通りです。複数のConvolutional layer (Conv. Layer)で入力画像から特徴量を抽出し、最後の全結合層(Conn. Layer)で物体が存在し得る領域の座標、物体種別の確率を計算します。単一のConvolutional Neural Networkのみで一般物体検出が実現できています。
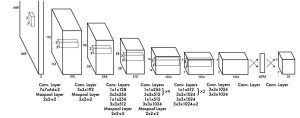
図3 YOLOのネットワーク
YOLOは、ソースコードも公開されていて処理が早いため、扱いやすいモデルだと思います。画像から様々な物体を検出する課題に取り組まれている方は是非試してみてください。
次回は、YOLOと比較されることの多いSSDについて紹介します!
参考文献
[1] Kiana Ehsani, Hessam Bagherinezhad, Joseph Redmon, Roozbeh Mottaghi, and Ali Farhadi, “You only look once: Unified, real-time object detection.” in CVPR2016.