前回、前々回と敵対的生成ネットワーク(GAN:Generative Adversarial Network)、DCGAN(Deep Convolutional Generative Adversarial Networks)を紹介しました。
第58回目の今回は、「Variational Autoencoder(VAE)」を紹介します。
オートエンコーダ (Autoencoder)
VAEを説明する前に、まずはそのもとのアイデアであるオートエンコーダ(Autoencoder)について説明します。
オートエンコーダは、日本語では自己符号化器と呼ばれるものです。ニューラルネットワークの一種で、入力データから次元を削減した特徴量を獲得することができます。教師データ無しで、訓練データのみで学習を行えます。つまり、画像一枚一枚に対して、猫が写っているなどのタグを人手により付与する必要がありません。
図1を見ながら具体的に説明したいと思います。
オートエンコーダはEncoderとDecoderで構成されています。Encoderでは、入力データの次元圧縮を行います。
Decoderでは、Encoderとは逆に次元圧縮されたデータからもとの入力を再現しようとします。元の入力と出力が一致するように学習するため、中間層である潜在変数zは入力のデータの特徴量を可能な限り保持することになります。つまり、オートエンコーダの中間層を抽出することで、次元圧縮として用いることができます。
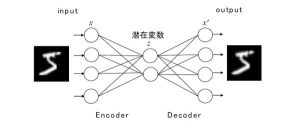
図1 オートエンコーダの概略
VAE (Variational Autoencoder)
オートエンコーダのEncoderとDecoderを別々に使うことができます。Encoderは前述のとおり、次元圧縮として用いることができます。一方、Decoderは未知の新しいデータを生成することに使用できます。つまり、生成モデルにも使うことができるという訳です。
Variational Autoencoder[1]は、AE(Autoencoder)の潜在変数部分に確率分布を導入したモデルです(図2)。μはガウス分布の平均、Σはガウス分布の分散です。確率分布を導入することで、多様な潜在変数をサンプリングすることが可能となり、その結果様々な画像を出力できます。
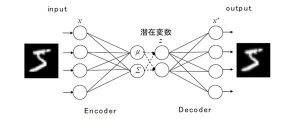
図2 VAEの概要
動画1の例は、VAEを手書き数字画像のデータセット(MNIST)で訓練し、得られた確率分布をもとに2次元状に潜在変数をサンプリングし、手書き数字画像を生成する過程を可視化したものです。学習が進むにつれて様々な手書き数字画像がより鮮明に生成できています。
動画1 VAEのネットワーク
また、VAEを顔画像データで訓練し、得られた確率分布をもとに2次元状に潜在変数をサンプリングし、顔画像を生成した結果が図3です。顔画像についても多様な画像が生成できていることが分かると思います。

図3 VAEによる画像生成
未知のデータを創り出すことができる生成モデル、夢がありとても面白い分野だと思います。是非一度試してみて下さい!
参考文献
[1] Kingma, Diederik P and Welling, Max. Auto-Encoding Variational Bayes. In The 2nd International Conference on Learning Representations (ICLR), 2013.